
Hasta ahora...he integrado R y SAP HANA via ODBC y via la integracion SAP HANA-R...pero habia dejado completamente de lado la capacidad OData de SAP HANA.
Para este blog, vamos a crear un simple Attribute View, exponerlo via SAP HANA y luego consumirlo con R para mostrar un bonito e impresionante grafico -;)
Primero, creemos el Attribute View y llamemoslo FLIGHTS. Este Attribute View estara compuesto por las tablas SPFLI, SCARR y SFLIGHT y va a devolver los campos PRICE, CURRENCY, CITYFROM, CITYTO, DISTANCE, CARRID y CARRNAME. Si se preguntan porque tantos campos? Solo para poder utilizarlos en otros campos -;)

Con el Attribute View listo, podemos crear un proyecto en el repositorio y los archivos necesarios para exponer el servicio OData.
Primero, creamos el archivo .xsapp...que deberia estar vacio -:P
Luego, creamos el archivo .xsaccess con el siguiente codigo...
| .xsaccess |
|---|
{
"exposed" : true,
"authentication" : [ { "method" : "Basic" } ]
}
|
Finalmente, creamos el archivo llamado flights.xsodata
| flights.xodata |
|---|
service {
"BlagStuff/FLIGHTS.attributeview" as "FLIGHTS" keys generate local "Id";
}
|
Con todo listo...podemos llamar a nuestro servicio para probarlo...podemos llamarlo ya sea como JSON o XML. Para este ejemplo, vamos a llamarlo como XML.

Ahora que sabemos que esta funcionando...podemos ir y programar en R -:D Para esto...vamos a necesitar 3 paquetes (Que pueden instalar via RStudio o en el mismo R), ggplot2, RCurl y XML.
| HANA_OData_and_R.R |
|---|
library("ggplot2")
library("RCurl")
library("XML")
web_page = getURL("XXX:8000/BlagStuff/flights.xsodata/FLIGHTS?$format=xml", userpwd = "SYSTEM:******")
doc <- xmlTreeParse(web_page, getDTD = F,useInternalNodes=T)
r <- xmlRoot(doc)
carrid<-list()
carrid_list<-list()
carrid_big_list<-list()
price<-list()
price_list<-list()
price_big_list<-list()
currency<-list()
currency_list<-list()
currency_big_list<-list()
for(i in 5:xmlSize(r)){
carrid[1]<-xmlValue(r[[i]][[5]][[1]][[2]])
carrid_list[i]<-carrid[1]
price[1]<-xmlValue(r[[i]][[5]][[1]][[8]])
price_list[i]<-price[1]
currency[1]<-xmlValue(r[[i]][[5]][[1]][[7]])
currency_list[i]<-currency[1]
}
carrid_big_list<-unlist(carrid_list)
price_big_list<-unlist(price_list)
currency_big_list<-unlist(currency_list)
flights_table<-data.frame(CARRID=as.character(carrid_big_list),PRICE=as.numeric(price_big_list),
CURRENCY=as.character(currency_big_list))
flights_agg<-aggregate(PRICE~.,data=flights_table, FUN=sum)
flights_agg<-flights_agg[order(flights_agg$CARRID),]
flights_table<-data.frame(CARRID=as.character(flights_agg$CARRID),PRICE=as.character(flights_agg$PRICE),
CURRENCY=as.character(flights_agg$CURRENCY))
ggplot(flights_table, aes(x=CARRID, y=PRICE, fill=CURRENCY)) + geom_histogram(binwidth=.5,
position="dodge", stat="identity")
|
Basicamente, estamos leyendo el servicio OData que viene en formato XML y convertirlo en un arbol para poder extraer sus componentes. Algo que puede llamar su atencion es que estamos usando xmlValue(r[[i]][[5]][[1]][[2]]) donde i comienza en 5.
Bueno...hay una explicacion sencilla -:) si accedemos nuestro arbol XML...el primer valor va a ser "feed", el segundo "id" y asi sigue...el quinto va a ser "entry" que es el que necesitamos. Luego para el siguiente [[5]]...dentro de "entry", el primer valor va a ser "id", el segundo "title" y asi sigue...el quinto va a ser "content" que es el que necesitamos. Luego para el siguiente [[1]]...dentro de "content", el primer valor va a ser "properties" que es el que necesitamos. Y para el ultimo [[2]]...dentro de "properties" el primer valor va a ser "id" y el segundo va a ser "carrid" que es el que necesitamos. Por cierto, xmlValue va a obtener el valor del tag XML -:P
En otras palabras...necesitamos analizar el esquema XML y determinar que debemos extraer...luego de eso, simplemente debemos asignar los valores a variables y crear nuestro data.frame.
Luego creamos una agregacion para sumar el valor del campo PRICE (En otras palabras, vamos a tener el campo PRICE agrupado por CARRID y CURRENCY), luego ordenamos los valores y finalmente creamos un nuevo data.frame para que podamos tener el campo PRICE como un caracter en vez de un numerico...solo para mejor presentacion del grafico...
Finalmente...llamamos al plot y estamos listos -:)
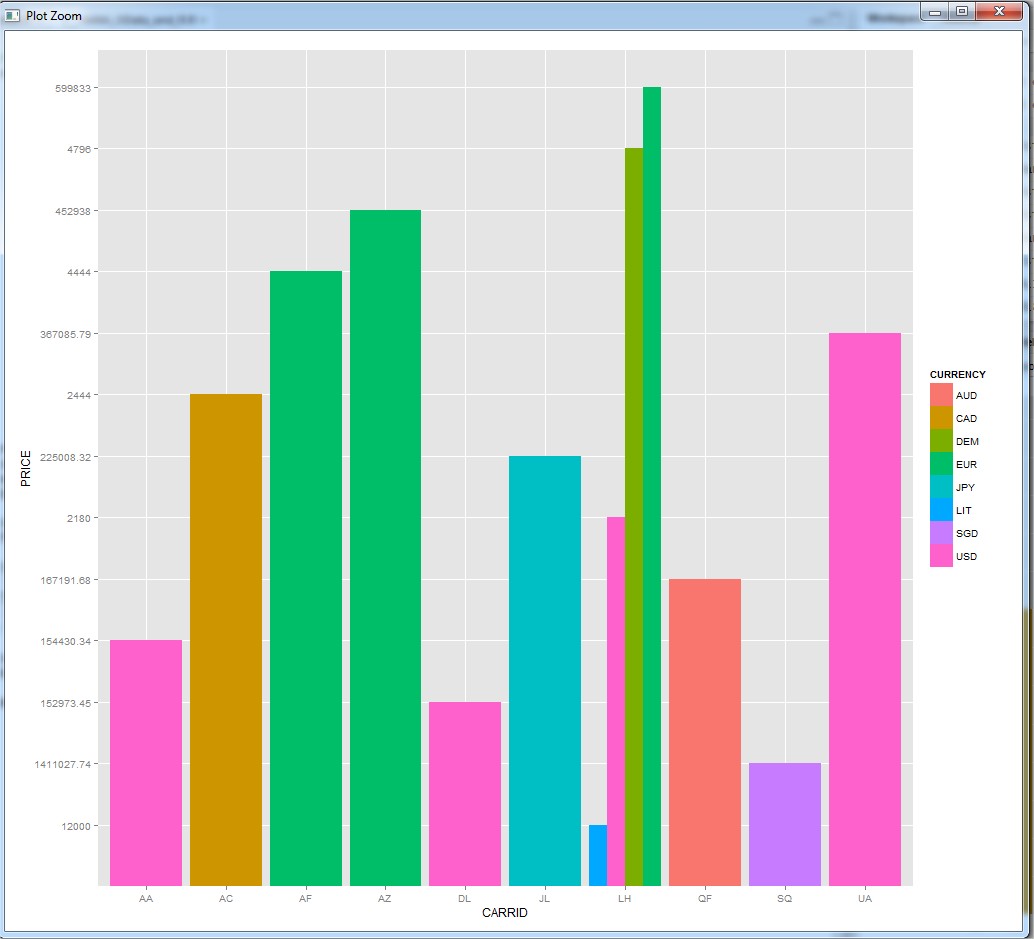
Feliz plotting! -:)
Saludos,
Blag.
No comments:
Post a Comment